![]()
This blog post intends to give a high-level overview of Spacemesh’s new SVM project and a brief overview of its future.
What is SVM? SVM is an acronym for “Spacemesh Virtual Machine.” Under the hood, it is based on wasmer WebAssembly runtime technology. This article assumes basic knowledge about what WebAssembly is, and related concepts like: host, module, import object, instance.
If you’re not familiar with these, I highly recommend reading some of the links under WebAssembly Articles at the end of this post.
SVM is designed for running smart contracts under any spacemesh full-node. There is a lot of excitement and anticipation around using WebAssembly outside of the browser, and blockchain-related projects are a popular use-case.
Running smart contracts transactions must produce the same output given the same starting point across each network node. It should run deterministically regardless of the operating system and hardware used.
Using WebAssembly for smart contracts is a good way to meet these fundamental requirements (i.e portability and determinism) because WebAssembly’s instructional abstractions are pretty low-level, while still remaining operating system and hardware agnostic. Another key selling point is that WebAssembly programs can call the host (a.k.a VM/runtime) for invoking functions (see: WebAssembly Imports).
Security is critical for running a smart contract under a full-node. WebAssembly programs run within a sandbox environment by design. This is another big point in favor of using WebAssembly.
SVM is essentially taking wasmer which is a general-purpose WebAssembly runtime, then extending and tailoring it to suit Spacemesh’s needs.
In point of fact, SVM could be leveraged by other blockchain projects that would like to have WebAssembly-based smart-contracts.
It is a standalone project, and like every line of Spacemesh code is 100% open-source: https://github.com/spacemeshos/svm
Now that we are all aligned with what SVM is trying to accomplish, let’s talk about its components.
Contract Storage
Each smart-contract has its own internal persistent storage. Without having disk persistence, we would not be able to run stateful programs. This would leave us with a feeble and trivial smart contracts solution.
Since we’re in the blockchain world, we need to be able to sync starting from a given snapshot point in time. Hence the contract storage is also snapshot-oriented. It means that operations performed on them will need an explicit context. We call that context/snapshot the contract state.
The contract state is derived from its underlying data, deterministically of course… more on this later.
The contract storage abstractions can be viewed hierarchically, with key-value being the most low-level abstraction and page slice cache the most high-level abstraction.
Let’s dig a bit deeper…
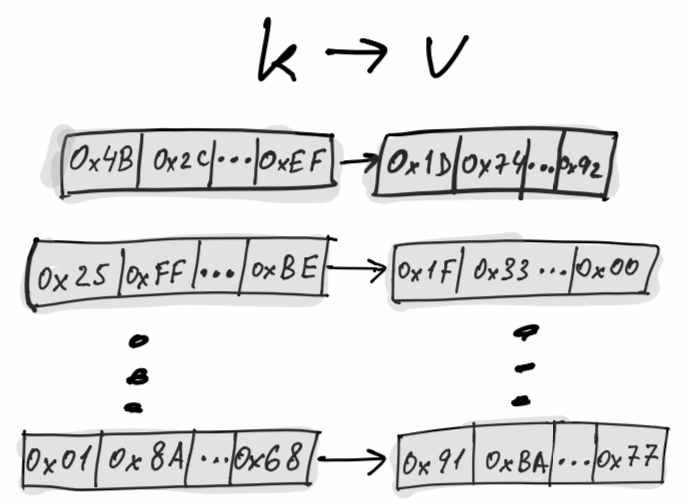
Key-value store
A key-value store maps between a slice of bytes denoting the key to another slice of bytes, representing the value. A key-value store is stateless. It isn’t aware of any contract state.
Currently, SVM has key-value interfaces for in-memory (useful for tests), leveldb and rocksdb.
The key-value store serves as a companion for other contract storage components.
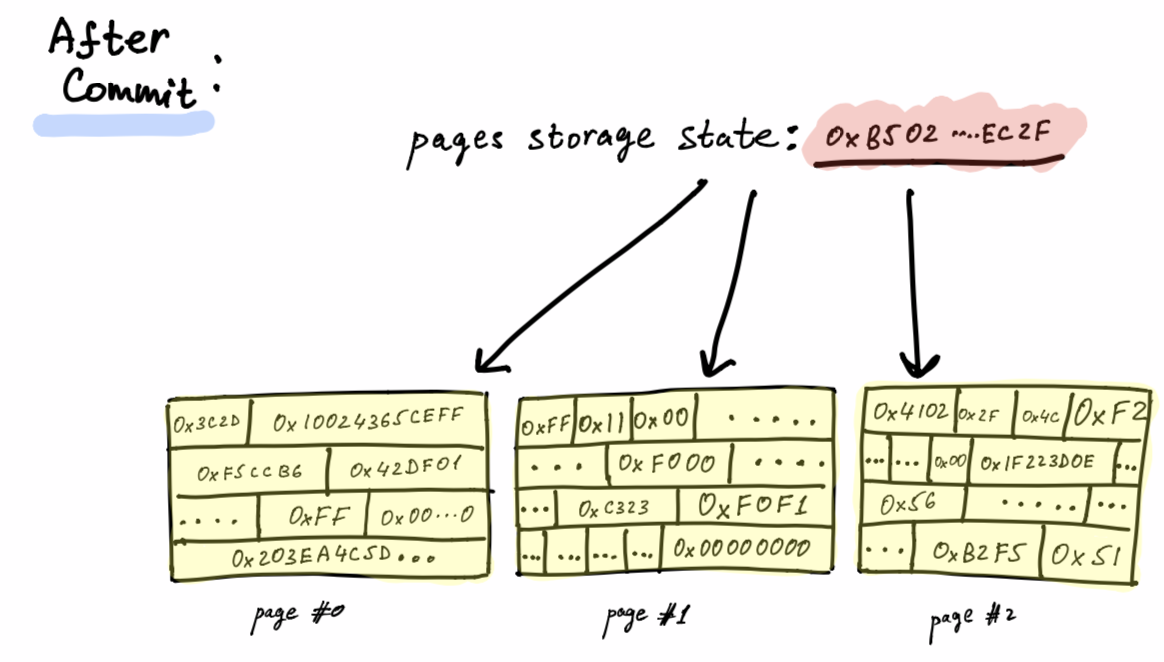
Pages Storage
In any standard strongly-typed programming language, the global variables are known ahead of runtime, during compile-time. This means that no new global variables can be added at runtime. The global variables are present throughout the lifetime of the program. (Maybe there are workarounds in some languages, but let’s just accept that the premise is sound for argument’s sake.)
Similarly, in SVM, we assume that each smart-contract program is aware, during its compile-time, of its storage needs. One program may require 5 variables of 32 bits each (20 bytes in total), while another program may use 2 booleans (1 byte each) and 4 integers of 64 bits resulting in 2 + 4 * 8 = 34 bytes.
Now, from the pages storage point of view, there are neither variables nor slices of bytes. From the pages storage point of view, there are only pages. Each page is a constant size (SVM is currently configured for a page size of 4096 bytes).
If, for example, our page size is defined as 10 bytes, then a program demanding 20 bytes for its variables will consume 2 pages. A program asking 32 bytes for its variables will use 4 pages. The last page will contain 2 used bytes, and 8 unused zeroed bytes.
Within a smart-contracts program, each page is assigned a numeric index. The page index is a sequential integer, local to the program, starting at 0. The first page of any program will have page index #0, the 2nd page will have page index #1 and so on.
The reason for that rough division it that we want to minimize disk access. Two adjacent program variables under the same page will trigger a “loading only” one page read operation.
Each program page has an associated hash, called the page hash. The page hash is derived from the contract account address, its page index, and raw content.
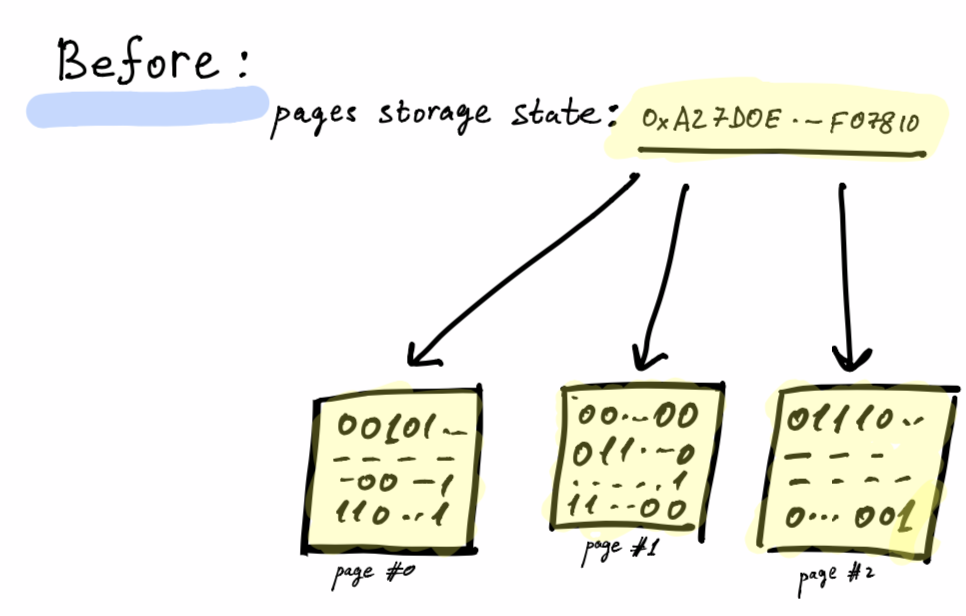
Page Cache
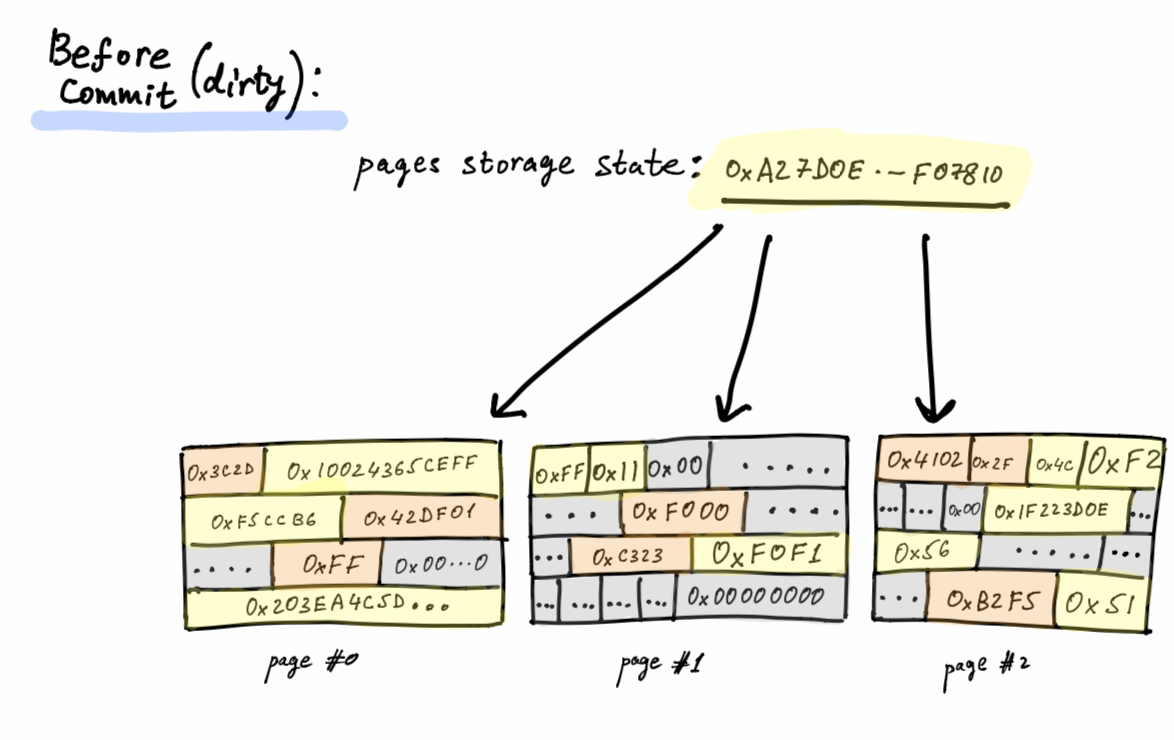
The page cache is a caching layer on top of pages storage. If during a program run we ask to load a page more than once, then only the first time will result in a disk hit (i.e. the Operating System will read the system-call, because as the Operating System has its own page cache, it will not physically hit the disk).
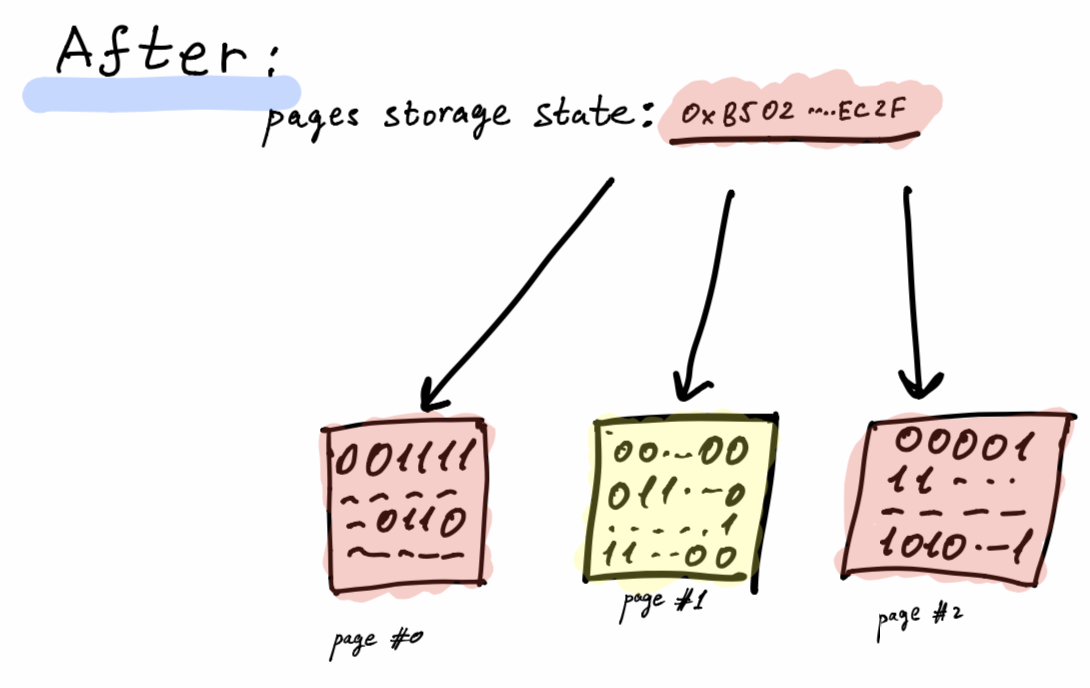
Once a running program issues a write-operation, we will mark the page as dirty. Committing the dirty pages via the page cache takes place only after the smart contract has finished its run. If the smart contract fails, we discard the dirty pages. The page cache interface isn’t able to access the smart-contracts code
The smart-contract only talks directly to the page slice cache, which we’ll explain next.
Page Slice Cache
The page slice cache is the top-level abstraction in the hierarchy. SVM smart-contracts talk directly only to the page slice cache (page slice for short). We’ll refer often to both page slice and contract storage interchangeably.
A running program trying to read a variable will translate to asking the SVM for the corresponding page-slice, which is an array of bytes representing that variable. A variable is an abstraction for running programs. There is no such thing as a variable for the contract storage, only page slices.
Each page slice has a sequential index, local to the program, starting at zero. So the compiled program top variable is, page slice #0, the next variable is page slice #1 and so on. I say “compiled program” because a compiler may decide to reorder variables as an optimization during the compilation phase.
If slice #0 of a program represents a boolean and slice #1 a 32 bit integer, we say that slice #0 is located under page #0, offset=0, length=1 and that slice #1 resides at page #1, offset=1, length=4.
So SVM programs deal with page slices. When we want to read slice #0 offset=0, length=1 for the first time, this request will translate to asking the page cache for page #0 which will result in a cache miss. Then, it’ll delegate the page load request to the underlying pages storage. The pages storage will infer the desired page hash, based on the current running contract address and contract state, and proceed to ask kv store for the actual fetch.
When SVM overrides a page slice, it will first make sure it’s been loaded, meaning the associated page to that page slice should be loaded. Then we’ll mark the page slice as dirty. When committing smart-contract changes upon successful execution, we will ask the page slice storage to commit only the dirty page slices which will translate to committing the associated dirty pages. Then we’ll compute the new page hash for each committed dirty page and calculate the new contract state, returning it as part of the execution receipt.
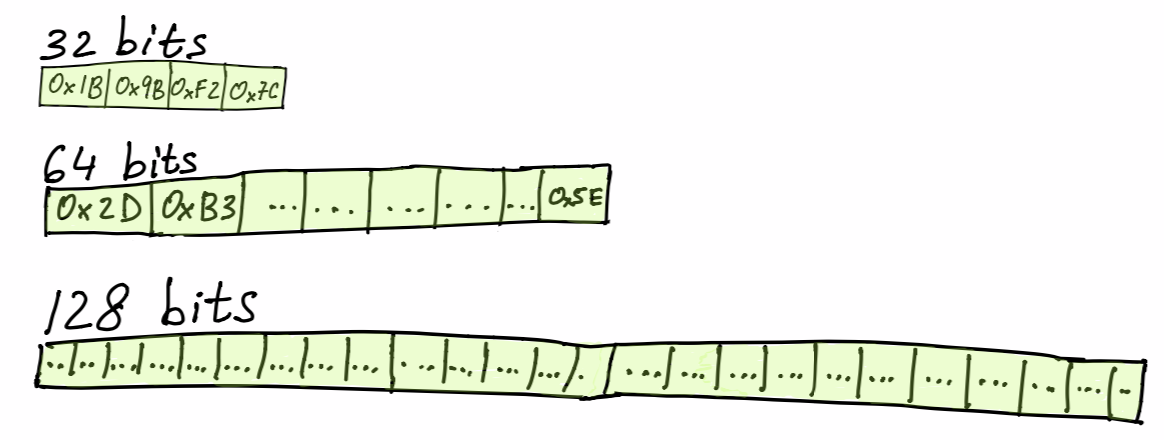
SVM Registers
SVM registers are non-persistent, ephemeral, fixed-sized buffers that make smart contracts run more smoothly. Each running SVM program can take advantage of these buffers when it would otherwise ask the runtime for more temporary memory cells, or use the runtime stack. Each running SVM program is currently initialized with their registers’ settings fixed at various sizes.
Additionally, using the registers’ API can add some readability to the program’s WebAssembly code. For example, let’s assume our full-node is using 20 bytes (<=> 160 bits) for account addresses and that a balance is represented as i64 (which is a WebAssembly primitive).
If we’d like to ask the full-node for a balance, given its account address under a register, we might come up with runtime vmcall like
svm_get_balance_from_reg(160, 1) -> i64
meaning:
“read register #1 of type 160 bits for the desired account address and return its balance as an i64 integer”.
Currently, the SVM registers’ settings for each running program consist of:
- 16 registers of 32 bits
- 16 registers of 64 bits
- 8 registers of 160 bits
- 4 registers of 256 bits
- 4 registers of 512 bits
These numbers are of course subject to change between SVM versions.
Another future initiative we may implement is adding the required registers’ settings necessary to run to the contract program metadata. That way, when we compile a high-level programming language targeted to the SVM flavored WebAssembly (see the SMESH section later), we’ll decide as part of the compilation process how many registers we’d like to have and how many of each type.
Runtime API
On top of the contract storage and contract registers lies the high-level SVM Runtime API as seen from the outside world. Basically, the runtime API should assist the full-node with the deployment of new contracts and executions of already deployed contracts. The Runtime API is a gateway from which SVM can be seen as a black box.
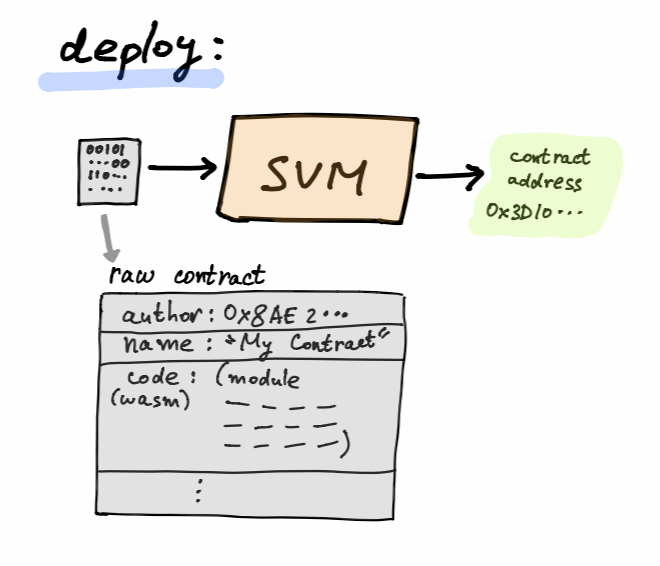
Deployment
So a new smart contract program has been born, and it’s being broadcast to the network as part of a contract deployment network transaction. Hopefully, it’ll be mined and get inserted into the chain (or ‘mesh’, in Spacemesh’s case).
Now, the process for the actual contract deployment within a full-node involves:
- Storing the contract under what we call a contract store
- Creating a new contract account. Its address will be deterministically derived from the contract deployment transaction. (author account address, author account nonce, contract code, etc.)
- Initializing the contract state to 00…00 (all zeros).
- Setting the initial account balance if stated (defaults to zero).
Now we’re ready to start executing smart contracts!
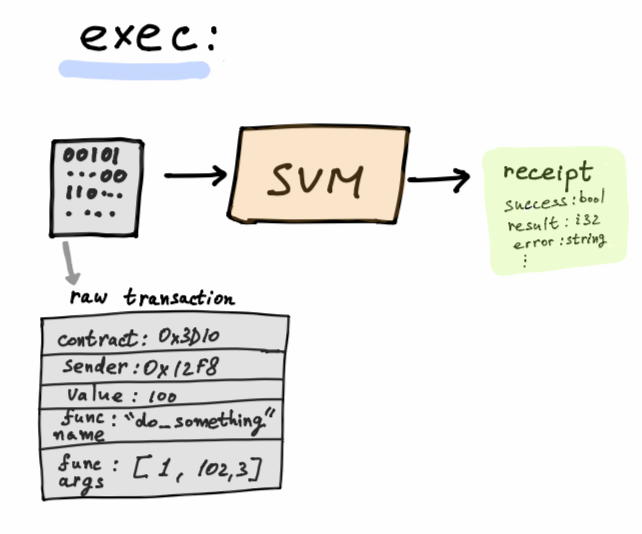
Execution
A smart contract execution transaction will contain:
- Contract address
- Transaction sender address
- Function name
- Function arguments
- Other
The Runtime will:
- Load the contract WebAssembly code from the contract store
- Compile it to native code, called a WebAssembly module - thank you wasmer!
- Create a WebAssembly import object with all SVM built-in vmcalls (storage/register/full-node)
The import object will be initialized with the contract address and contract state provided by the full-node.
- Instantiate a new SVM instance, which is to say instantiate a wasmer instance, with the crafted import object.
- Call the desired function with its given arguments.
- Return a receipt. For now, it will only say whether the program execution succeeded or failed.
If the receipt reported a success, we commit all the storage changes to the contract storage and compute the new contract state. Otherwise, we discard the storage pending changes and remain with the same contract state.
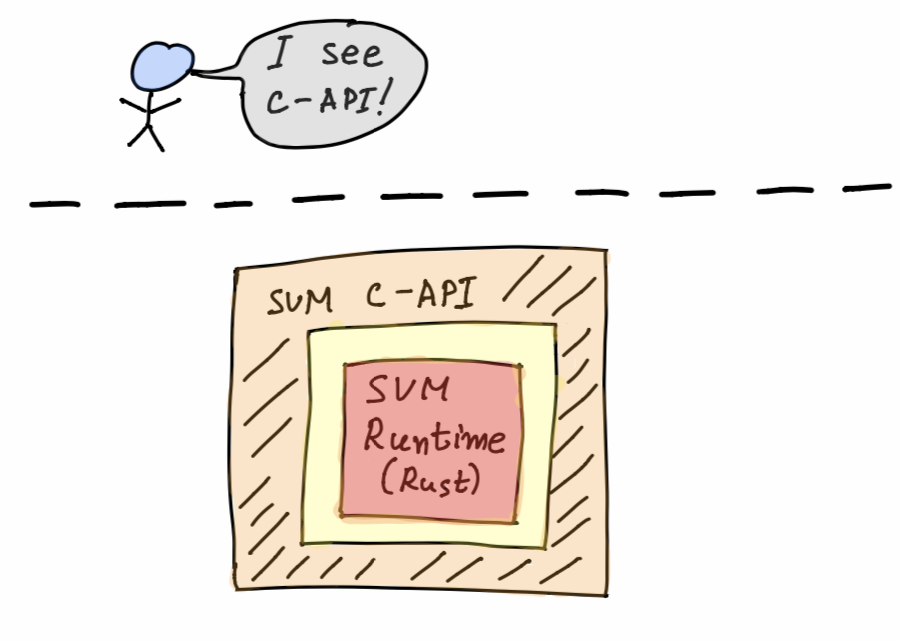
Runtime C-API & Golang binding
wasmer, and therefore SVM, is written in Rust. Thankfully Rust has FFI bindings to C ABI. This allows Rust to call C and vice versa. We care about C calling Rust functionality. wasmer comes with its own C-API out of the box. SVM has its own FFI API exposed (using the wasmer c-api internally).
Spacemesh full-node is written in Golang, which can interface with C ABI code using cgo. So in order to integrate SVM with the Spacemesh full-node, we should introduce a glue layer of Spacemesh full-node cgo to SVM Runtime C-API.
Luckily, wasmer has a Golang client, go-ext-wasm, and there is now a go-ext-wasm Spacemesh fork that adds that glue layer for SVM’s needs.
Roadmap
The first SVM milestone is now being stabilized. So what’s next?
So here’s a brief about the future of SVM:
Storage Unbounded Data-Structures
The current SVM only supports fixed-size storage variables. There is no support for unbounded data-structures. We’d like to gradually add support for these data-structures:
- list
- map
- set
- sorted-set
Each unbounded data-structure will manage its own state. The root contract storage will store these data-structures state in the same way it stores booleans/integers. It’s like having a reference type variable. This will be possible because the reference/data-structure state will be of a fixed size.
Having these unbounded data-structures adds complexity to the contract storage, which will have to additionally track the changes of each unbounded data-structure.
Committing contract storage changes will now first require computing each unbounded data-structure’s new state, and updating the contract storage along with its matching page slice. Only after that can we perform a batch commit of all the storage changes in one shot.
Actually, this is a recursive process, since an unbounded data-structure may also hold unbounded data-structures. For example: say we have a list of maps, or a map from string to list. This means we’ll need to traverse the innermost unbounded data-structures first, setting off a chain reaction whereby each data-structure notifies its parent about its new state – until finally reaching the top-level contract storage (what we have today).
We need to do more research on how to represent each unbounded data-structure. We may end up having an MPT Ethereum-style for each such data-structure. Maybe different data-structures will have different methods for managing their states.
Gas Metering
This, of course, goes without saying. We can’t let a program run forever due to the halting problem. We are still thinking of how to make the gas metering more elegant if possible. More on this in future posts.
Contract to Contract Calls
We’ll want to have an explicit distinction between a contract calling another contract, as opposed to using another library/package/dependency. As long a program relies on libraries, it will not issue a call to other accounts. In every other case, we want to retain the ability to explicitly call another contract, resulting in the spawn of a new SVM instance. There is more info about using dependencies here: Code Reuse.
Structured Events with expiration
We want to be able to add structured events for easier searching, and we’d like to set an expiration on them in order to save disk space. If a program desires permanent events, the solution is to use a general contract storage variable. (see Storage Unbounded Data-Structures above).
Code Reuse
One of the big must-haves for SVM runtime is the ability to let programs reuse code written by other people. We’d like SVM programs to be able to use other packages of code. SVM smart contracts should be able to call not only runtime built-in vmcalls, but also other packages loaded upon instantiation. Part of these packages may be written in any programming language compiled to WebAssembly (see also SMESH).
These packages may not be associated with other contracts accounts (as we are not sure how it will be represented yet), but they still must be stored on-chain. It’s like having access to RubyGems/npm/crates.io or other package managers accessible on the chain. (documentation or debugging info will be stored off-chain).
I know there is early-stage work being done on the interoperability of WebAssembly modules. A few weeks ago, Lin Clark published a great article about WebAssembly Interface Types. This seems to be a big step in that direction.
I can imagine feeding a wasmer module along with its dependencies modules and compiling it natively under one executable unit of code. Or maybe instead of having one compiled module, we can tell wasmer that, when we build the import object, we’re interested not only in the predefined runtime vmcalls, but also in the functions that exist in other WebAssembly modules, serving as dependencies. In such a case we could look at programs as importing runtime dynamic vmcalls.
This idea is analogous to having an operating system with pre-compiled built-ins (like system-calls) vs. dynamically loading kernel modules at runtime.
SMESH
The puzzle will never be complete without having a high-level-friendly programming language that will compile to SVM WebAssembly code. (i.e WebAssembly using the SVM runtime vmcalls). Initial planning is already underway for this future programming language, under the name SMESH. The actual work on SMESH will probably start before reaching all the SVM milestones described above. I’ve given a talk about the motivation for SMESH here.
Summary
In this article, we reviewed the work being done so far for SVM - Spacemesh Virtual Machine, and the motivation behind it. Then, we talked about the next steps for SVM and mentioned SMESH, the future high-level programming language that will compile to SVM WebAssembly code.
In order to fulfill these ambitious goals, we’ve made room for more people to join.
So if you are a Rust developer interested in compilation and programming languages, please don’t be shy! Reach out using any of the various communication methods available, including but not limited to:
or you can send me an email directly: yaron.wittenstein@gmail.com
If you’re interested in contributing to SVM, please take a look at the SVM issues page. Please contact us before starting any work, so that we can get on the same page.
We also provide gitcoin bounties 💰💰 for contributors.
References
- Spacemesh
- SVM
- wasmer
- go-ext-wasm Spacemesh
- Spacemesh full-node
- Spacemesh smart contracts research
- Spacemesh contact page